
前言
树链剖分是我学会的第一个高级数据结构, 它的模板甚至都比我以前所写过的任何数据结构题更加复杂, 代码量也更大, 我意识到, 我的代码能力已经不会再拖累我学任何东西了, 从现在开始, 一切重点都在于思路和理解
但也正是在此之后, 我逐渐发现我在这方面前进的太远了, 学会这种东西的纪念意义远比实际意义要大, 因为初中能参加的比赛根本考不到, 我常常发现数据结构的那些好题常常会因为其它部分卡住没法做, 这让人沮丧
因此, 我重新拾起了写笔记的念头, 把艰深的概念以我自己的方式记录下来, 相信对于我来说, 它会比任何其他的维基之类更加容易理解, 我将这部分知识封存, 在以后需要它的时候, 再迅速地重新捡起
正如同海莲拉芙所说, “人类发明了文字, 懂得写成并印刷成书籍, 我们便不再徒劳无策地只受时间的摆弄宰割, 我们甚至可以局部地, 甚富意义地击败时间”
简介和一些理解
人们常说, 如果一个题不够难, 那就把它放到树上, 如果一个题太难, 那就把它放到链上
树链剖分正是采用这样的思路, 通过 DFS 序将整棵树分为一些树链 ( 可以简单理解为树上的一条链 ) , 使得每个节点都包含且仅包含在一条树链上
而如果我们将这些树链首尾相连, 树就变成了一条链, 即线性的序列, 这样我们就可以将它放到任何可以维护序列的数据结构上了
树链剖分将对树链的正常操作 ( 树链加, 树链修改, 查询树链和等 ) 拆分成对转换后的链的一系列操作, 用数据结构实现, 树链剖分保证对于
文字实现
以下的概念是针对树链剖分中的重链剖分而言
对于任一节点, 若用
对于任一非叶子节点, 我们定义它最重 ( 重量最大 ) 的子节点为重子节点, 剩余子节点均为轻子节点
我们用如下的步骤进行树链剖分:
- 从根节点开始, 从它向它的重子节点引一条边
- 从这个重子节点向这个重子节点的重子节点引一条边
- 重复步骤 2 , 直到遇到叶子节点, 我们称从根节点到该叶子节点的树链为一条重链
- 将根节点剩下的所有轻子节点分别作为根节点, 重复步骤 1 到 3 , 直到所有的节点均属于一条重链 ( 只有一个轻子节点的链也被称为重链 )
一些额外的定义:
- 连接到一个重子节点的边称为重边, 一条重链是由重边组成的
- 连接到一个轻子节点的边成为轻边, 树上不会出现连续的两条轻边
- 一条重链中唯一的轻子节点 ( 即上文所述的根节点 ) 称为重链的顶
- 树链剖分保证树上的任意一条包含
个节点的路径至多划分为 条重链 ( 的一部分 )
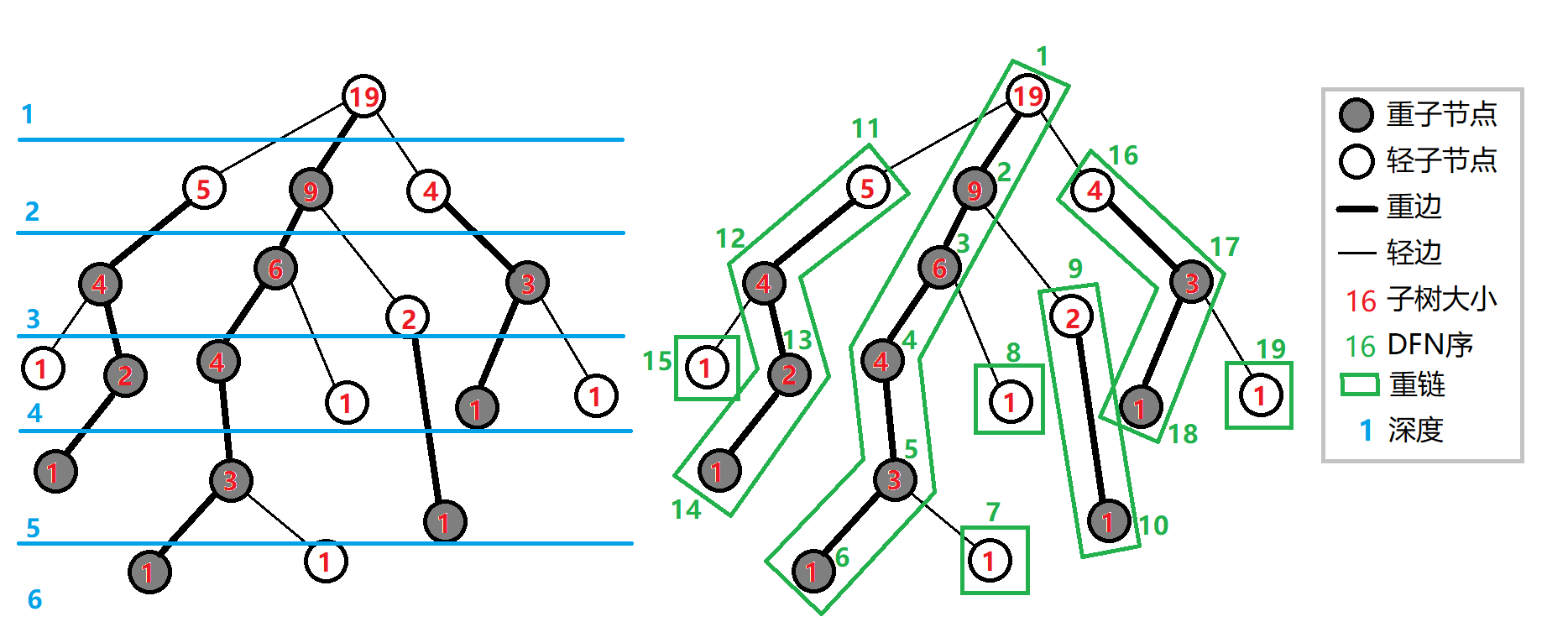
我们用树链剖分过程中访问每个节点的顺序对节点进行重新标号, 称为节点的 DFS 序 ( 或称为 DFN 序 ) , 我们按照 DFS 序将重链首尾相连, 并放入数据结构
如下图, 若按照从左到右的层序对其进行标号, 则数据结构中所存储的节点标号将为: 1->3->6->11->16->18->19->12->7->13->17->2->5->10->15->9->4->8->13->14:
代码实现
类似于树形 DP , 我们首先要通过第一次 DFS 获取我们所需要的元信息, 如子树的大小 sizes , 节点的深度 depths , 节点的重子节点 sons 和节点的父亲节点 fathers
具体实现如下:
void get_sons(int index, int father)
{
sizes[index] = 1; // 子树大小至少为 1
for (auto son : edges[index])
{
if (son == father) { continue; } // 防止重复访问
fathers[son] = index;
depths[son] = depths[fathers[son]] + 1;
get_sons(son, index); // 填写子节点的重量
sizes[index] += sizes[son]; // 将子节点重量累加到自己身上
if (sizes[son] > sizes[sons[index]]) { sons[index] = son; } // 通用最值算法求出重子节点
}
}
然后我们要将整棵树划分为重链, 令 to_order 表示节点的 DFS 序, to_node 表示 DFS 序代表的节点, tops 表示节点所处的重链的顶, counter 为一个初始化为 0 的计数器, 则具体实现如下:
void chaining(int index, int top)
{
node_to_order[index] = ++counter;
order_to_node[counter] = index;
tops[index] = top;
if (sons[index]) { chaining(sons[index], top); } // 连接到重子节点, 顶不变
for (auto son : edges[index])
{
if (son == fathers[index] || sons == sons[index]) { continue; } // 不访问父亲节点和重子节点
chaining(son, son); // 以此子节点为顶, 引一条新的重链
}
}
如果我们使用线段树来维护, 参数表如下:
void push_up(int current);
void push_down(int from, int to, int current);
void build(int from, int to, int current);
int query(int left, int right, int from, int to, int current);
void modify(int left, int right, int from, int to, int current, long long modifier);
则我们可以写出支持查询树链和, 查询子树和, 树链修改和子树修改的代码:
int chain_query(int from, int to)
{
int answer = 0;
while (tops[from] != tops[to]) // 先把查询的两个点放在一条链上
{
if (depths[tops[from]] < depths[tops[to]]) { swap(from, to); } // 优先跳深度较深的节点, 两个节点交替跳
// 下面处理 from 当前所在的链
// from 和 from 所在链的顶一定在同一条链上, 可以查询, 将结果加入答案
// 查询后说明当前链已经处理完毕, 即让 from 跳到 from 所在链的顶的父亲节点, 离开当前链
answer += query(node_to_order[tops[from]], node_to_order[from], 1, n, 1);
from = fathers[tops[from]];
}
if (depths[from] < depths[to]) { swap(from, to); } // 同一条链上, 更深的节点 DFS 序一定更大
answer += query(node_to_order[to], node_to_order[from], 1, n, 1); // 两点此时已经在同一条链上, 可以查询
return answer;
}
int tree_query(int root)
{
// 同一棵子树的 DFS 序一定是连续的, 且根节点的 DFS 序最大
// 因此子树在线段树上是连续的, 且区间的开头是根节点的 DFS 序
return query(node_to_order[root], node_to_order[root] + sizes[root] - 1, 1, n, 1);
}
void chain_modify(int from, int to, int modifier) // 与 chain_query 类似, 不再介绍
{
while (tops[from] != tops[to])
{
if (depths[tops[from]] < depths[tops[to]]) { swap(from, to); }
modify(node_to_order[tops[from]], node_to_order[from], 1, n, 1, modifier);
from = fathers[tops[from]];
}
if (depths[from] < depths[to]) { swap(from, to); }
modify(node_to_order[to], node_to_order[from], 1, n, 1, modifier);
}
void tree_modify(int root, int modifier) // 与 tree_query 类似, 不再介绍
{
modify(node_to_order[root], node_to_order[root] + sizes[root] - 1, 1, n, 1, modifier);
}
切记, 用线段树 ( 或其它任何数据结构 ) 只能查询 / 修改在同一条链上的数据, 我们所作的一切操作都是为了将查询 / 修改的区间放在同一条链上
加上取模操作, 此代码可以通过 P3384 树链剖分这道模板题
P2590 树的统计
树链剖分裸题, 要求树上单点修改, 查询树链和, 查询树链最大值, 那么可以开一棵节点是结构体的线段树, 维护区间和和区间最大值, 都支持单点修改即可
主函数部分如下:
cin >> n;
for (int i = 1; i < n; i++)
{
cin >> x >> y;
edges[x].emplace_back(y);
edges[y].emplace_back(x);
}
for (int i = 1; i <= n; i++) { cin >> weights[i]; }
depths[1] = 1;
fathers[1] = 1;
get_sons(1, -1);
chaining(1, 1);
build(1, n, 1);
cin >> q;
while (q --> 0)
{
cin >> type >> x >> y;
if (type == "CHANGE") { tree_modify(node_to_order[x], 1, n, 1, y); }
else if (type == "QSUM") { cout << sum_query(x, y) << endl; }
else { cout << max_query(x, y) << endl; }
}
其余同模板
P3178 树上操作
树链剖分裸题, 要求树上单点加, 子树加, 查询树链和, 代码见模板
P2146 软件包管理器
树链剖分经典题, 不难发现这棵树的点权只有 0 或 1 , 代表未安装和已安装, 则安装操作抽象为将该节点到根的链上所有点修改为 1 , 卸载操作抽象为将以该节点为根的子树全部修改为 0
主函数部分如下:
cin >> n;
for (int i = 2; i <= n; i++)
{
cin >> node;
edges[i].emplace_back(node + 1);
edges[node + 1].emplace_back(i);
}
depths[1] = 1;
fathers[1] = 1;
get_sons(1, -1);
chaining(1, 1);
cin >> q;
while (q --> 0)
{
cin >> type >> node;
node++;
if (type == "install")
{
before = tree[1];
chain_modify(1, node, 1);
after = tree[1];
cout << abs(after - before) << endl;
}
else
{
before = tree[1];
tree_modify(node, 0);
after = tree[1];
cout << abs(after - before) << endl;
}
}
P5354 由乃的 OJ
接下来是重头戏, 一道 Ynoi2017 的题目
引入
这道题的题面中提到了, 它是 P2114 起床困难综合症的强化版, 原本是在线性数据上做贪心, 现在要求带修改, 并且上树
总结一下弱化版题面: 要求一个
弱化版用到的技巧是二进制操作中的常见技巧, 即拆位, 对于每一位分别做决策, 各位之间互不影响, 每一位各自最大, 则整体最大
给出一份参考的实现的核心代码, 虽然这不是重点; 注意区分操作前的选择和操作后的选择的区别, 不要混为一谈:
// 枚举时必须从高位到低位, 不然无法得知是否会超过 m
// 每次决策时, 若选 1 操作后更大且选 1 不会超过 m 则选择 1
// 其余情况都选 0 ( 包括二者在该位等效的情况 )
for (int i = 63; i >= 0; i--)
{
zero = false;
one = true;
for (int j = 1; j <= n; j++)
{
temp = (num[j] >> i) & 1ull;
if (operator_[j] == "AND")
{
zero &= temp;
one &= temp;
}
else if (operator_[j] == "OR")
{
zero |= temp;
one |= temp;
}
else
{
zero ^= temp;
one ^= temp;
}
}
if (zero >= one || (1ull << i) > m)
{
if (zero) { answer |= 1ull << i; }
}
else
{
if (one) { answer |= 1ull << i; }
m -= 1ull << i;
}
}
cout << answer << endl;
解决
首先解决带修的问题, 将上述解法拓展: 每次求取一个二进制位从序列最左侧经过操作到达序列最右侧后的值, 然后依此进行贪心, 可以启发我们存储一个二进制串, 使得其中每一位分别维护上面所述的信息, 把这个串放在线段树上维护即可实现单点修改
下一步很显然, 把这个序列上树, 只需要加一层树剖; 因为二进制串最长为 64 位, 故可用 unsigned long long 存储, 能消掉一个常数的时间复杂度, 则最终是
实现上, 我们知道, 所有树链都可以分成两部分: 从起点到 LCA ( 最近公共祖先 ) 和从 LCA 到终点, 注意这个过程是有顺序的: 在前一部分, 在剖分后的线性结构上所体现的是, 从左侧向右侧遍历, 至于后一部分则相反, 体现为从右侧向左侧遍历, 这显然是有区别的, 故从左到右和从右到左的操作结果都需要存储
对于每次询问, 拆成上述的两部分, 然后再把两部分的结果合并一次, 这里推荐采用重载节点加法运算符的写法, 如下:
Node operator+(Node self, Node other)
{
Node result;
result.l0 = (self.l0 & other.l1) | (~self.l0 & other.l0);
result.l1 = (self.l1 & other.l1) | (~self.l1 & other.l0);
result.r0 = (other.r0 & self.r1) | (~other.r0 & self.r0);
result.r1 = (other.r1 & self.r1) | (~other.r1 & self.r0);
return result;
}
当然了, 我们需要给节点一个无参数构造函数来初始化它:
Node()
{
this->l0 = 0;
this->l1 = ~0; // 0 取反即为全 1
this->r0 = 0;
this->r1 = ~0;
}
一定一定不要写成这样, 会占用莫名其妙的极大空间导致无可挽回的 MLE :
struct Node
{
int l0 = 0, l1 = ~0, r0 = 0, r1 = ~0;
};
剩下部分没有太多难度, 只给出解决询问的部分代码, 细节很多, 具体见注释:
Node to_x, to_y, raw;
int lca_ = lca(x, y), zero, one;
ull answer = 0;
while (tops[x] != tops[lca_]) // 让 x 跳到 lca_ 所在的链上
{
to_x = query(to_order[tops[x]], to_order[x], 1, n, 1) + to_x; // 重载的加法符合交换律, 顺序无关
x = fathers[tops[x]];
}
to_x = query(to_order[lca_], to_order[x], 1, n, 1) + to_x; // 让 x 跳到 lca_ 处
while (tops[y] != tops[lca_])
{
to_y = query(to_order[tops[y]], to_order[y], 1, n, 1) + to_y;
y = fathers[tops[y]];
}
if (y != lca_) { to_y = query(to_order[lca_] + 1, to_order[y], 1, n, 1) + to_y; } // 注意 lca_ 不要重复统计了, 还要考虑 y 就是 lca_ 的可能性
swap(to_x.l0, to_x.r0);
swap(to_x.l1, to_x.r1);
raw = to_x + to_y;
for (int i = 63; i >= 0; i--)
{
zero = (raw.l0 >> i) & 1;
one = (raw.l1 >> i) & 1;
if (zero >= one || (1ull << i) > z)
{
if (zero) { answer |= 1ull << i; }
}
else
{
if (one) { answer |= 1ull << i; }
z -= 1ull << i;
}
}
cout << answer << endl; // 以上贪心和上面弱化版贪心一致
LCA 如何求
上面的过程中提到了 LCA , 树剖是 LCA 的一种求法, 而且很好写
思路如下:
- 如果两个点在同一条链上, 那么深度较小的点是 LCA
- 如果两个点不在同一条链上, 那么链顶深度较大的点优先向上跳, 每次跳到链顶的父亲节点即可
具体代码如下:
int lca(int a, int b)
{
while (tops[a] != tops[b])
{
if (depths[tops[a]] < depths[tops[b]]) { swap(a, b); }
a = fathers[tops[a]];
}
if (depths[a] < depths[b]) { return a; }
return b;
}